
PLEASE NOTE: This information is provided to assist you in editing and updating EHM. Please do not use the information in here to dump data from EHM for other purposes / games.
The purpose of posting this information here is to help any other users who might be interested in editing EHM or simply having a poke around in the .dat files. It also provides the opportunity for other users to share any scripts they have written. Maybe, if there are other users interested in using C/C++ to edit EHM, we can help each other improve our code and figure out anything we're struggling with.
To get started you'll need an IDE. This is something that allows you to write your code and to compile it. I have been using Microsoft Visual C++ 2010 Express which can be downloaded from here for free. An alternative to MSVC++ is Code::Blocks - this is another free IDE which I hear is also very good.
Before I share my first snippet, I thought I'd give some step by step instructions on how to create a C/C++ project in MSVC++ and how to paste the code I've written. Perhaps this might help any users who may be interested in trying out C/C++ but are unsure how to get started. These steps should only take about four or five minutes to carry out:
1) Load MSVC++. If you are using Windows Vista or 7 then it is best to run it is administrator because otherwise some of your code may not work (e.g. if you write a script to modify the data in the RAM to change the start date, it won't work unless you are running as admin. You can do this by right-clicking on the MSVC++ shortcut -> Properties -> Compatibility -> tick the box entitled 'Run this program as an administrator.'
2) In MSVC++, click on File -> New -> Project.
3) In the New Project window, select 'CLR Empty Project'. At the bottom of the window, give your project a name (I will call mine Dat Example). You will also see at the bottom of the window details of where your project will be saved (make a mental note of this).
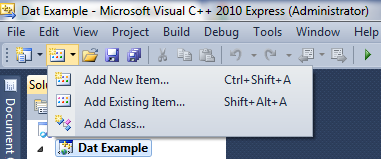
4) Once you have clicked on OK to create your project, you will be presented with a blank window. From the toolbar at the top of the window, click on the Add New Item icon and select Add New Item from the menu:
5) From the Add New Item window, select C++ File (.cpp) and give your .cpp file a name (you'll see the Name box at the bottom of the window). I'll call mine dat_example. Click on OK to create the file.
6) As we will be exporting the data from EHM, we will need to use the EHM database format/structure. This can be downloaded here. Open the downloaded ZIP file and extract the three .h files (database_flags.h, database_types.h and language_types.h) to the location of the .cpp file you created in step #5.
You can find your .cpp file by going to the location of your project (remember in step #3 I said make a mental note of this). For example, my project is stored here: D:\Documents\Visual Studio 2010\Projects\Dat Example\. Within this folder there is another folder of the same name - i.e. D:\Documents\Visual Studio 2010\Projects\Dat Example\[n]Dat Example\[/b]. This is where you will find your .cpp file and this is where you should place the three .h files.
Btw, .h files are C/C++ header files.
7) In MSVC++, click on the Add New Item icon and click on Add Existing Item. Select the three .h files. You can hold down the CTRL key to select all three files at once. After you click on OK you will see the three .h files listed in the Header Files section in the Solution Explorer (left hand side of the main window).
8) Your dat_example.cpp file should be open within the middle section of the window. If it is not then double click its name in the Solution Explorer (left hand side of the main window).
9) Copy and paste the code quoted below into your .cpp file (i.e. by pasting it into the middle section of your window.
10) The code below will convert index.dat into a csv file. You will need to place a copy of index.dat in the same folder as your .cpp file. Grab a copy of index.dat from any EHM database and put it in the correct location. As mentioned in step #6, on my computer, this would be: D:\Documents\Visual Studio 2010\Projects\Dat Example\[n]Dat Example\[/b].
11) Click on Debug -> Start Debugging or simply press F5 on your keyboard to load your script. Once the script has finished, it should say "Press ENTER to close this window." Press ENTER and your script will exit.
12) If you navigate to the location of your .cpp file, you will see a new file named index.csv has been created. Double-click on this file and it should open in Excel (or otherwise open it in Notepad). You will see that the contents of index.dat are now nicely formatted and readable. Hey presto!
By modifying the code below, you could open any of the .dat files in EHM and export all or just some of the data to csv. I have used index.dat for my example because it is a small file and therefore the simplest example.
Here's the code:
Code: Select all
#include <iostream>
#include <fstream>
#pragma pack(1) // This is essential because the data in the .dat files are byte-swapped
#include "database_types.h" // The three EHM database format .h files must be called after #pragma pack(1)
#include "database_flags.h"
#include "language_types.h"
using namespace std; // As we are just using the standard library, we'll use std namespace for ease of reference
int main() {
fstream dat_infile ("index.dat", ios::in | ios::binary); // Open index.dat for reading in binary mode. We'll call it dat_infile.
fstream csv_outfile ("index.csv", ios::out); // Create a blank index.csv file in text mode. We'll call it csv_outfile.
struct INDEX dat; // Within the database_types.h file the structure of index.dat INDEX
// We'll assign "dat" as the identifier for use with this structure
// Calculate the length of index.dat and call is dat_filesize:
dat_infile.seekg (0, ios::end);
auto dat_filesize = dat_infile.tellg();
dat_infile.seekg (0, ios::beg);
if (dat_infile.is_open()) // If index.dat has been successfully opened then perform the following code within the {} braces
{
dat_infile.seekg(INDEX_IGNORE_DATA,ios::beg); // DELETE THIS LINE IF YOU ARE OPENING ANY FILE OTHER THAN INDEX.DAT
// The first 8 bytes of index.dat are blank and therefore we must skip over these. Hence the reason of the line above.
// A loop to read the data stream into the buffer one record at a time and save it as a csv file
while( dat_infile.tellg() < dat_filesize )
{
dat_infile.read ((char*)&dat, sizeof(INDEX));
csv_outfile << dat.filename << "," << dat.file_id << "," << dat.table_sz << "," << dat.version << endl; // Commas are added between each field as per csv file format. The final field of each record is terminated by a new line - i.e. 'endl'.
}
// Close the index.dat and index.csv files
dat_infile.close();
csv_outfile.close();
}
else // If index.dat cannot be opened then do the following
{
cout << "Unable to open index.dat" << endl;
}
cout << "Press ENTER to close this window.";
cin.get(); // Wait until the user has pressed ENTER before closing the window
return(0); // Exit the script / close the window.
}
Here are a couple of notes:
#pragma pack(1)
You must include this at the top of your code. The data in EHM is byte-swapped (the bytes are stored in reverse order) and so you must include the above line in order to ensure that your script accounts for this. This line must be placed before you call your three .h header files.
if (dat_infile.is_open()) { }
This states what the script will do if index.dat (i.e. dat_infile as it is referred to in my script) is successfully opened. You can add an else { } structure afterwards if you want the script to do something if the file couldn't be opened. You'll see I've use the else { } structure to display a message saying that the file couldn't be opened. You don't have to include else { } if you don't want to, but it can help when debugging.
Looping through to the end of the file
In order to read each record at a time, I have use a loop like so:
Code: Select all
while( dat_infile.tellg() < dat_filesize )Code: Select all
dat_infile.seekg (0, ios::end);
auto dat_filesize = dat_infile.tellg();
dat_infile.seekg (0, ios::beg);The loop of while( dat_infile.tellg() < dat_filesize ) { } loops through the entirety of the file until it reaches the end. Some people use eof() to loop through the file but this doesn't work correctly because it will read the final record in the file twice (because the EOF flag isn't set until after it has reached the end of the file). My advice is to stick with my method of first calculating the file size and then using this in conjunction with tellg() in the loop.
dat_infile.seekg(INDEX_IGNORE_DATA,ios::beg);
Unlike all of the other .dat files, index.dat starts with eight bytes that are not used to store data. Therefore, when you read/write to index.dat you will need to skip over the first eight bytes. For ease of reference, I have added INDEX_IGNORE_DATA to the version of database_types.h that is stored on TBL. You could equally use the following instead of INDEX_IGNORE_DATA:
Code: Select all
dat_infile.seekg(8,ios::beg);dat_infile.read ((char*)&dat, sizeof(INDEX));
Within the loop mentioned above, we read through the data each record at a time. The sizeof(INDEX) tells the script how much data to read at once. sizeof(INDEX) returns the size (in bytes) of each record. If you wanted to know the size in bytes of the records in index.dat, you could display this on the screen by adding cout << sizeof(INDEX); somewhere within the code. You don't have to read the file to calculate the size - it is calculated based upon the structure info from the database_types.h file.
csv_outfile << dat.filename << "," << dat.file_id << "," << dat.table_sz << "," << dat.version << endl;
This line saves each record to your csv_outfile (i.e. index.csv). You'll see that I've added commas between each field followed by a new line (endl) at the end of each record. This is so that the data is saved in csv format. You can do whatever you want with this line. For example, you could add spaces, make it display over multiple lines, export just some of the fields, change the order of the fields, etc etc.
The dat. part of each field name refers to the identifier that we gave the INDEX struct earlier on in the code (struct INDEX dat;). The bit after .dat refers to the field names. You will find the field names in database_types.h.
Adapting this code for other .dat files.
This is fairly straightforward to do:
- Change the reference to index.dat in fstream dat_infile ("index.dat", ios::in | ios::binary); to whichever file you want to open. You can also change the reference index.csv to whatever you want to name your output csv file.
- Change the reference to INDEX to the name of the struct which relates to the .dat file you want to open. You will find this in the database_types.h file (e.g. CLUBS is used for club.dat). There are two references in my script that you will need to change: struct INDEX dat; and dat_infile.read ((char*)&dat, sizeof(INDEX));.
- Don't forget to remove the dat_infile.seekg(INDEX_IGNORE_DATA,ios::beg); line!
- Change the csv_outfile << dat.filename << "," << dat.file_id << "," << dat.table_sz << "," << dat.version << endl; line according to the fields you want to export.
One final note: If you find that you are getting strange symbols being exported instead of numbers then try adding static_cast<int>() to the field names where you save the data to csv_outfile. E.g. csv_outfile << dat.filename << "," << static_cast<int>(dat.file_id) << "," << static_cast<int>(dat.table_sz) << "," << static_cast<int>(dat.version) << endl;
Good luck!
